
빅데이터 분석 기사 작업형 3유형 변경, 예시문제
빅데이터 분석기사, 줄여서 빅분기.
작업형 3유형이 6회 시험부터 다르게 출제됩니다.
시험환경 체험 사이트 : 제3유형 (풀이용, 제출없음) - 체험하기 (goorm.io)
구름EDU - 모두를 위한 맞춤형 IT교육
구름EDU는 모두를 위한 맞춤형 IT교육 플랫폼입니다. 개인/학교/기업 및 기관 별 최적화된 IT교육 솔루션을 경험해보세요. 기초부터 실무 프로그래밍 교육, 전국 초중고/대학교 온라인 강의, 기업/
edu.goorm.io
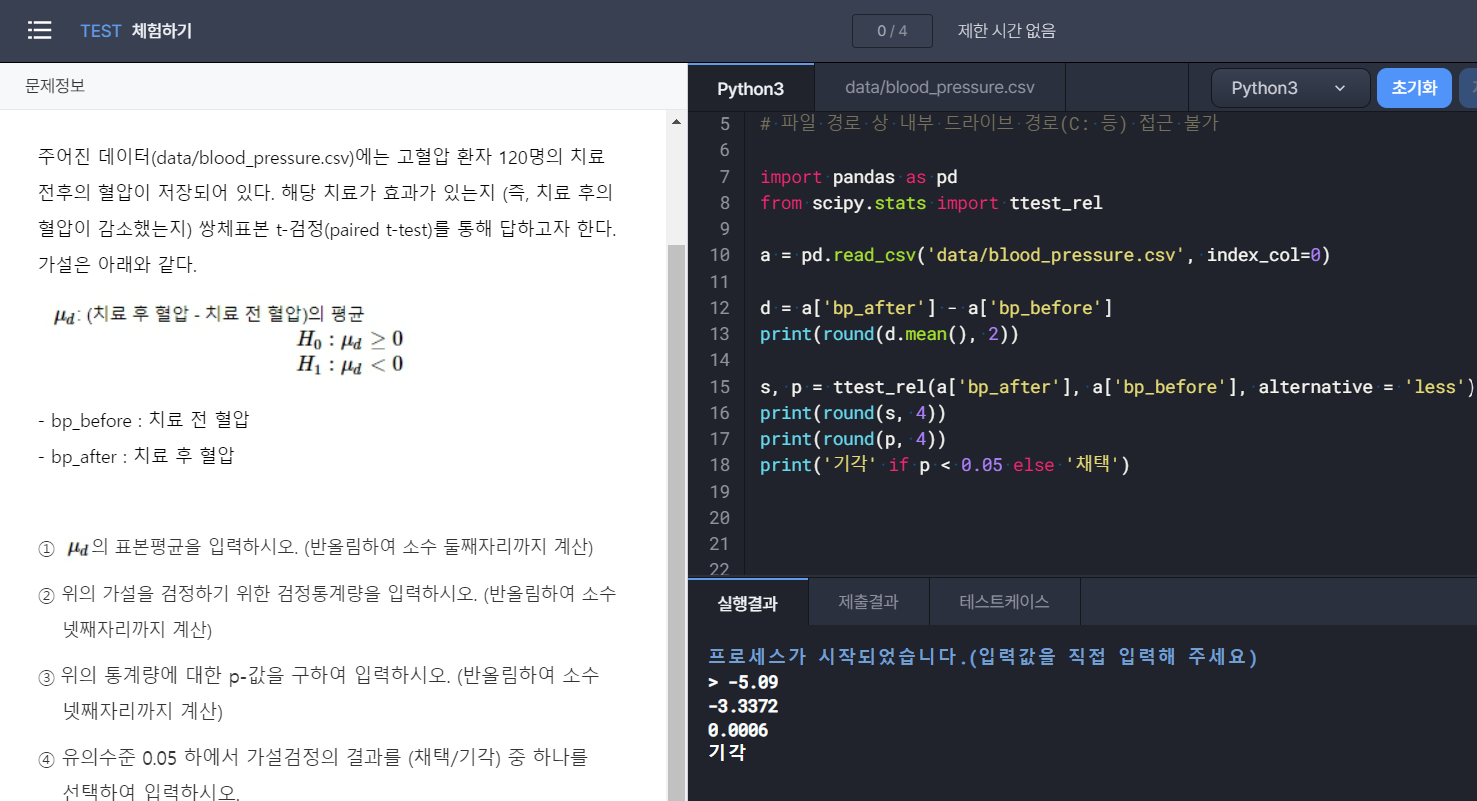
주어진 데이터(data/blood_pressure.csv)에는고혈압 환자 120명의 치료 전후의 혈압이 저장되어 있다.
해당 치료가 효과가 있는지 (즉, 치료 후의 혈압이 감소했는지) 쌍체표본 t-검정(paired t-test)를 통해 답하고자 한다.
가설은 아래와 같다.
- bp_before : 치료 전 혈압
- bp_after : 치료 후 혈압
①(치료 후 혈압 - 치료 전 혈압)의 표본평균을 입력하시오. (반올림하여 소수 둘째자리까지 계산)
②위의 가설을 검정하기 위한 검정통계량을 입력하시오.(반올림하여 소수 넷째자리까지 계산)
③위의 통계량에 대한 p-값을 구하여 입력하시오. (반올림하여 소수 넷째자리까지 계산)
④유의수준 0.05 하에서 가설검정의 결과를 (채택/기각) 중 하나를 선택하여 입력하시오.
예시문제 풀이
1) 표본 평균 구하는 방법
import pandas as pd
a = pd.read_csv('data/blood_pressure.csv', index_col=0)
d = a['bp_after'] - a['bp_before']
print(d.mean())
2) 쌍체표본 t-검정(paired t-test)으로 검정 통계량 구하기
import pandas as pd
from scipy.stats import ttest_rel
a = pd.read_csv('data/blood_pressure.csv', index_col=0)
s, p = ttest_rel(a['bp_after'], a['bp_before'], alternative = 'less')
print(round(s, 4))
3) 쌍체표본 t-검정(paired t-test)으로 p-값 구하기
import pandas as pd
from scipy.stats import ttest_rel
a = pd.read_csv('data/blood_pressure.csv', index_col=0)
s, p = ttest_rel(a['bp_after'], a['bp_before'], alternative = 'less')
print(round(p, 4))
4) 유의수준 0.05 하에서 가설검정의 결과 (채택/기각) 중 하나를 선택
import pandas as pd
from scipy.stats import ttest_rel
a = pd.read_csv('data/blood_pressure.csv', index_col=0)
s, p = ttest_rel(a['bp_after'], a['bp_before'], alternative = 'less')
print('기각' if p < 0.05 else '채택')
예시 문제 결과 스크린샷
앞으로의 본격적인 꿀팁!
각종 출판사나 전문가의 의견으로는 3유형으로 아마도 t-test, 카이제곱, ANOVA 문제가 나올 것으로 예상됩니다.
다음 포스팅에는 모수 검정인 t-test, ANOVA에 대해 다루도록 하겠습니다.
'IT.데이터' 카테고리의 다른 글
| 빅데이터 분석기사 실기 - 작업형 2유형 준비 / 평가 함수, 사용 라이브러리 import (0) | 2023.06.20 |
|---|---|
| 빅데이터 분석기사 실기 - 작업형 3유형 준비 / 카이제곱, 피셔의 정확 검정 (Fisher's Exact Test), 비모수 검정 (0) | 2023.06.20 |
| 빅데이터 분석기사 실기 - 작업형 3유형 준비 / t-test, ANOVA (0) | 2023.06.19 |
| GUID 파티션 테이블 GPT(GUID Partition Table) Partition Structure Analysis (0) | 2023.05.03 |
| CHAT GPT에 대하여 (0) | 2023.05.03 |




댓글